[教程]vps应用之搭建自己的笔趣阁小说采集站
一直在网络上看小说,闻名遐迩的笔趣阁,肯定知道。
看到好多小说站都是叫笔趣阁,估计都是是采集的
前几天翻万能GitHub,发现了这个笔趣阁的程序
于是拿来,试用了一下,搭建了自己的笔趣阁,终于不用看别人站上的广告了
弄个教程出来,给有闲置VPS的哥们参考玩玩。
源代码:https://github.com/woytu/ygbook
本文使用宝塔lNMP环境搭建
需要VPS的,推荐搬瓦工产品,点击这里
如何搭建宝塔 lnmp环境,看上面这个链接
接上面的,添加好域名后
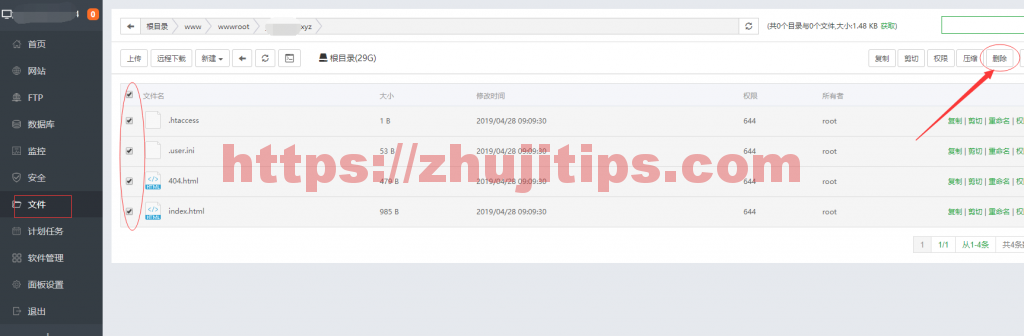
左侧点击文件,进入刚添加的网站目录,里面有4个默认创建的文件,全选,删除!
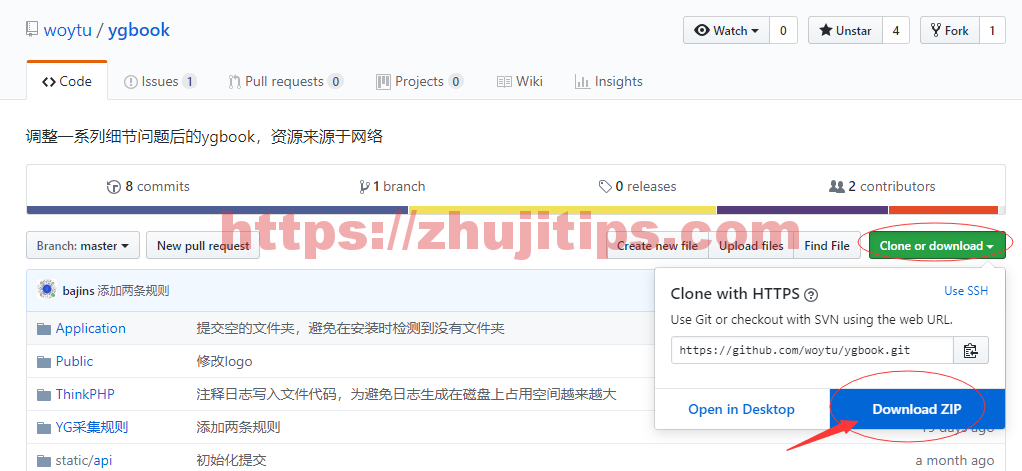
去github上,找到下载链接,右键download zip,选:复制链接地址
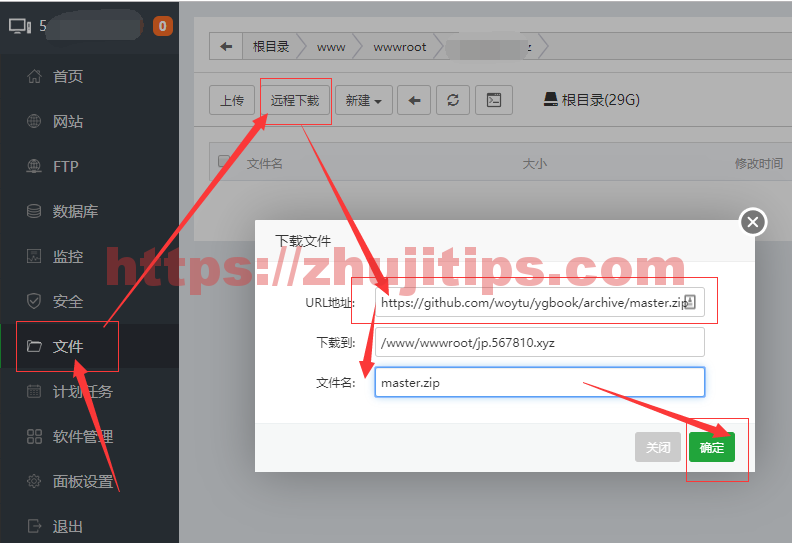
使用宝塔的远程下载功能,下载源码
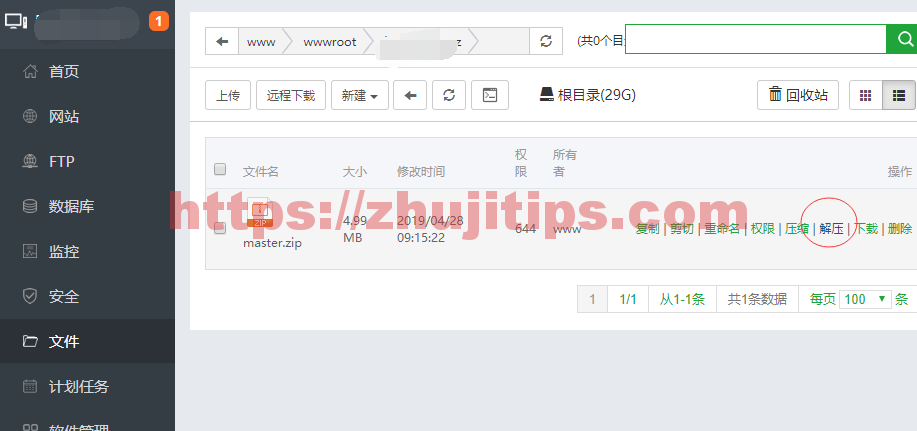
点击解压
进入刚解压的目录中,全选,剪切或者复制都行,回到网站根目录(上一级目录),黏贴
现在目录结构应该是这样的,把刚那个解压的目录删除后,如上图
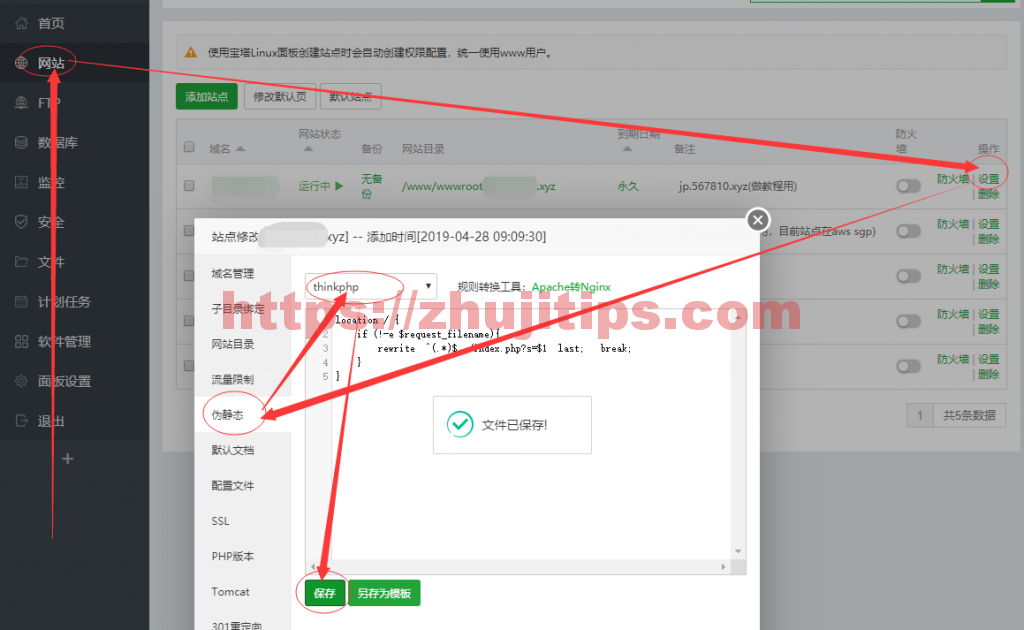
去刚添加的网站中,进行伪静态设置,看箭头一步步点,就是了。
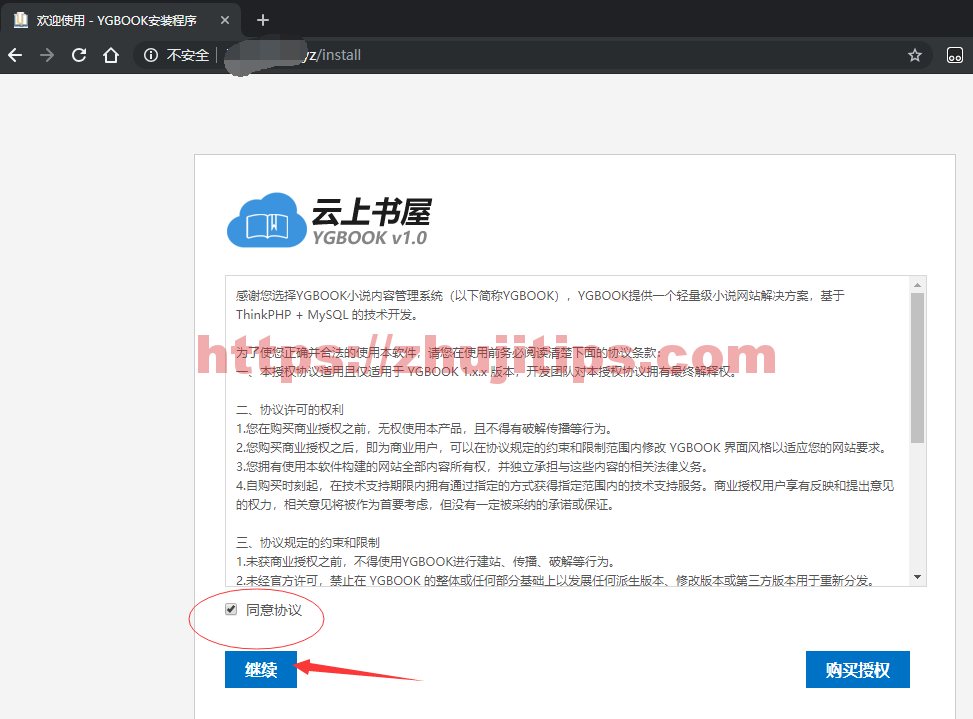
在浏览器中输入,添加的域名网址,自动会跳转到/install,勾选,继续。

点击,继续
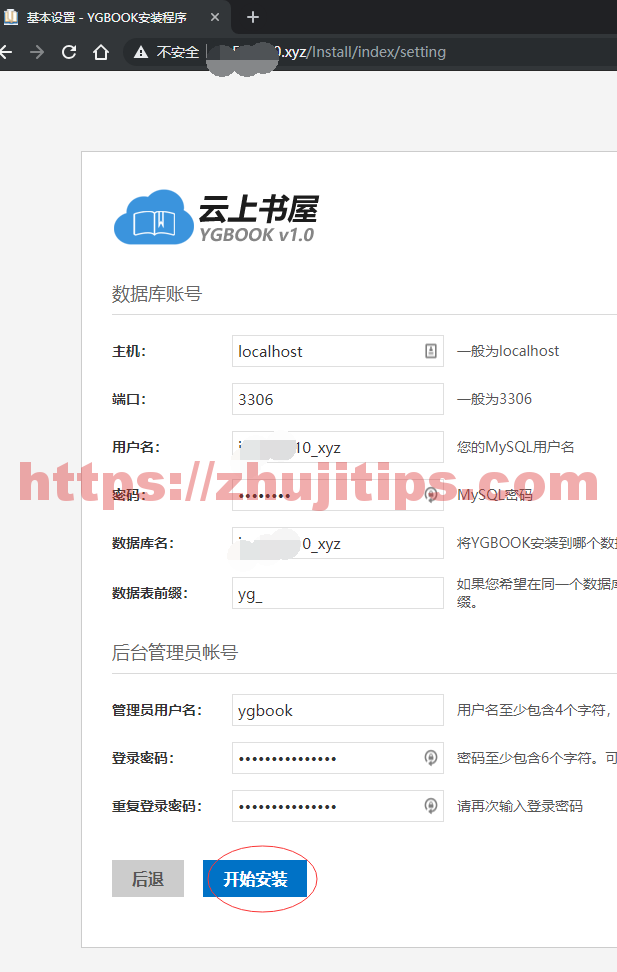
填写你创建网站时的数据库用户名数据库名及密码,管理员用户名不用改,改什么,这个系统自动会改成admin,注意,登录时用户名admin
登录后台
到此,程序搭建完毕,但是是空的,还没书
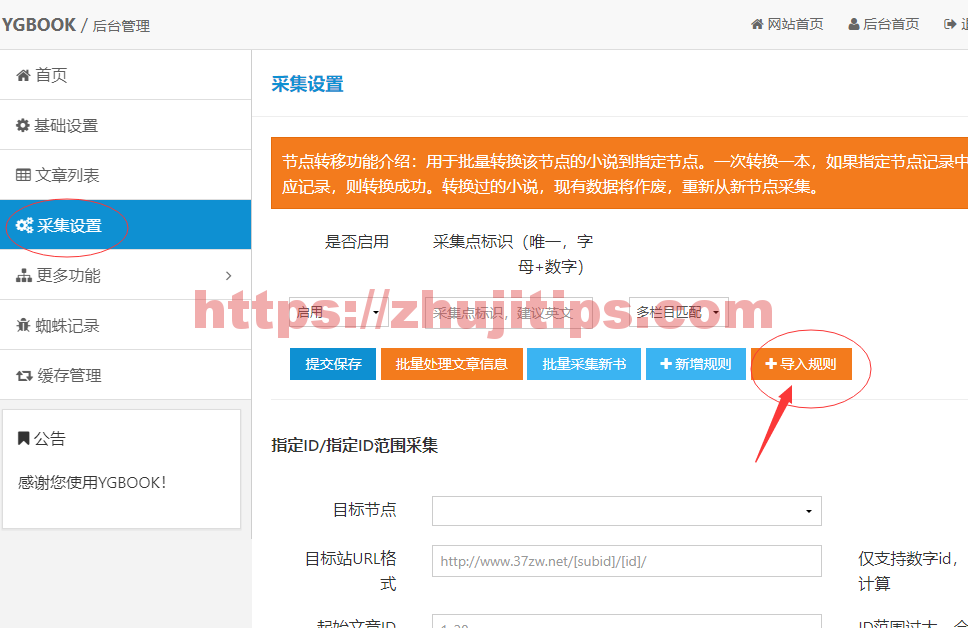
采集设置中,点导入规则
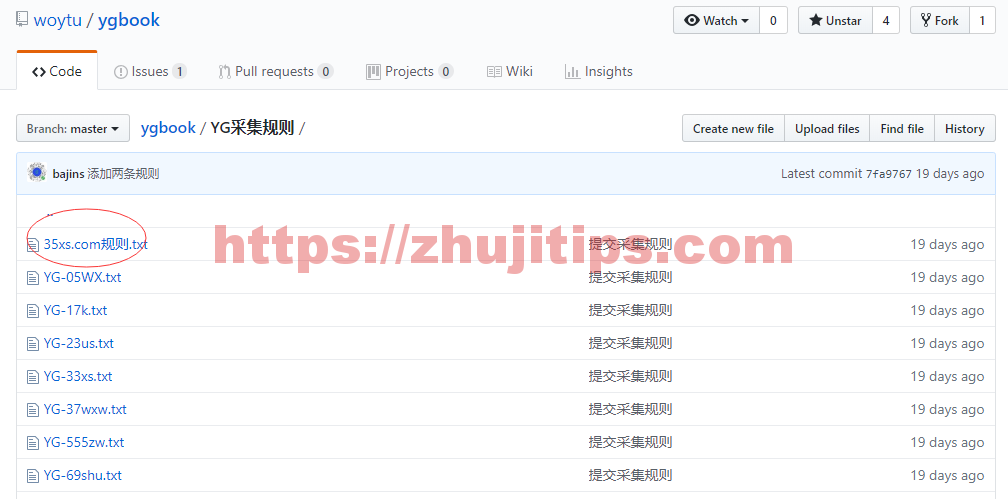
去github上yg采集规则中,找到这个地方,随便点开一个
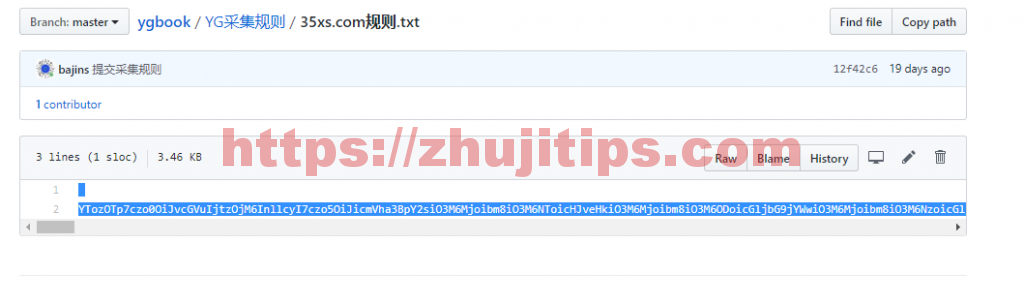
复制这段乱码
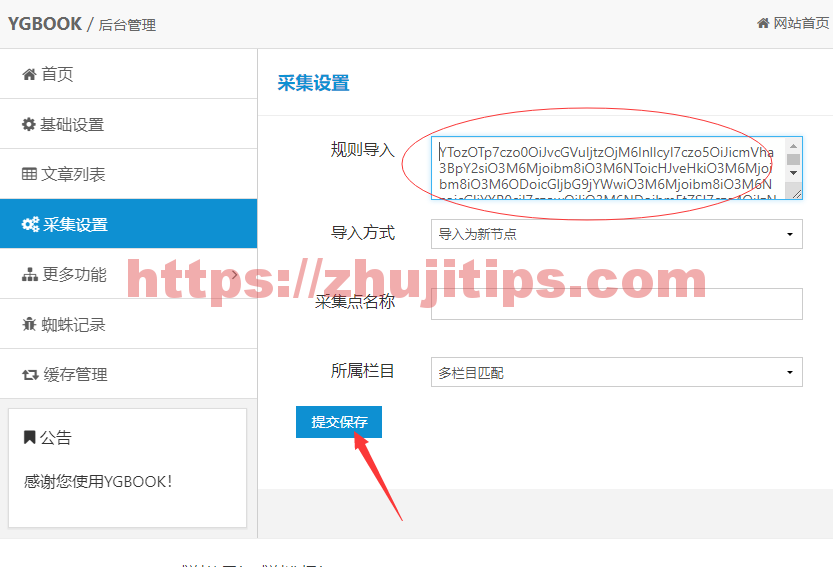
在规则导入中,贴入这段代码
上面有好多不同网站的采集规则,自行添加多个吧
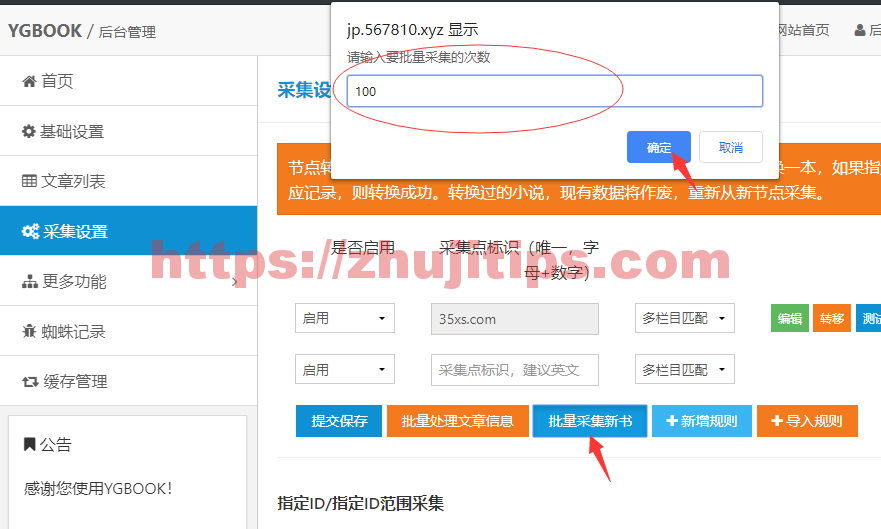
点击批量采集新书,跳出弹框,10-100之间,不能多了,点击确定,就开始采集了
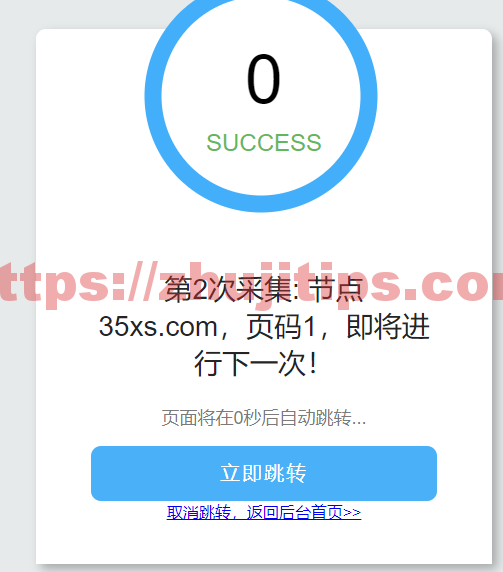
如果需要n次数
用这个
http://abc.com/index.php?s=/Admin/Index/pick/action/runpick/nownum/1/maxnum/99999.html
abc.com换成你自己的网址。后面99999.html的99999这个数字,你要多少就设置多少
已经有了
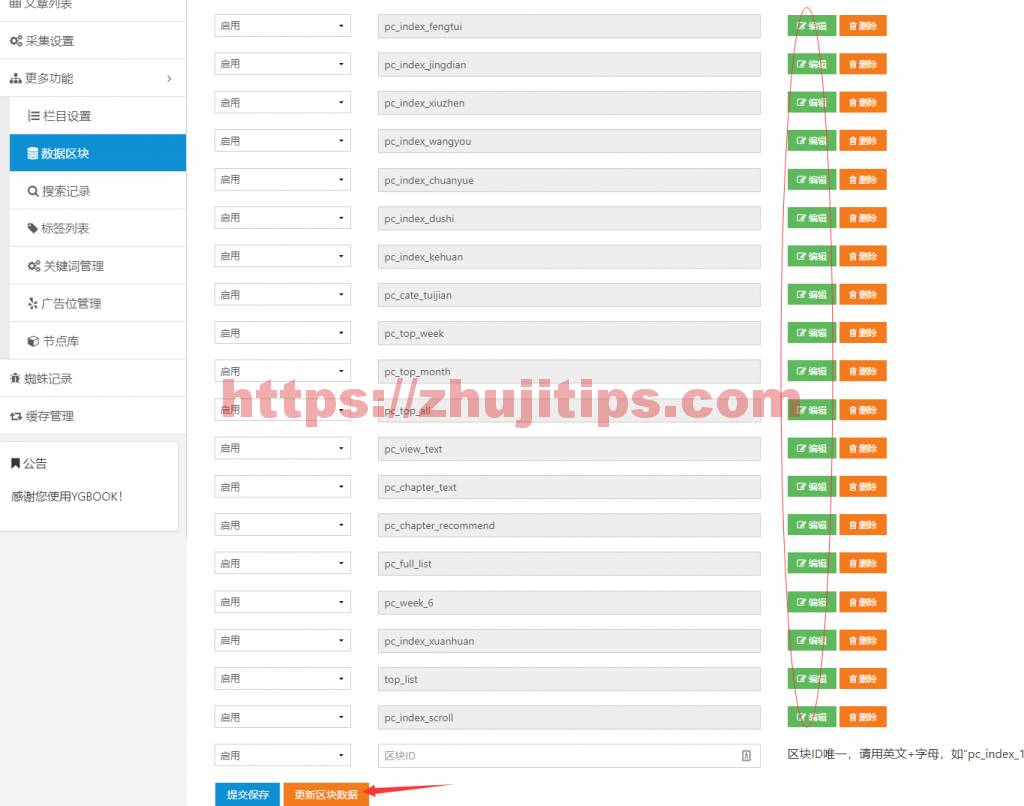
有些前台页面显示不正常,需要在数据区块这些里面,给他调整一下
然后,更新区块数据
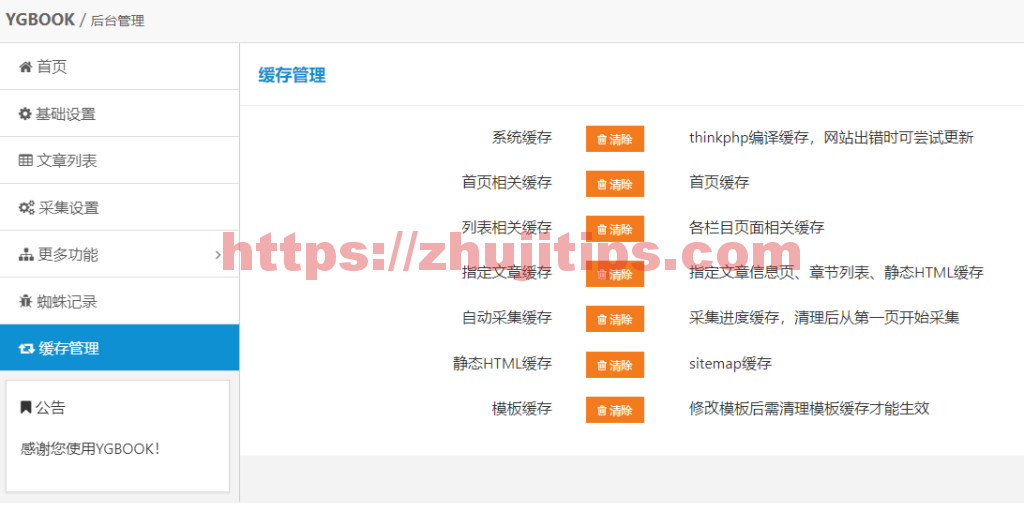
在缓存管理中,清除一下
最后,还有个问题,以为是程序毛病,后来发现正常了:
刚开始书本采集的比较少,进行测试的时候,点击分类,如玄幻,历史,等,vps cpu100%
后来,书本采集了多了,发现再去点击各个分类,这个问题没有了。
GOOD LUCKS!
END